A Breakdown Of How Lopdf Reads Pdfs
Below is a breakdown I wrote for myself while reading through lopdf. It’s raw and not really intended for the general reader, but if you’re interested in how lopdf works, you might find it useful.
This document is a breakdown of how lopdf parses PDFs.
All of the data in the PDF is parsed into a Document struct:
/// PDF document.
#[derive(Debug, Clone)]
pub struct Document {
/// The version of the PDF specification to which the file conforms.
pub version: String,
/// The trailer gives the location of the cross-reference table and of certain special objects.
pub trailer: Dictionary,
/// The cross-reference table contains locations of the indirect objects.
pub reference_table: Xref,
/// The objects that make up the document contained in the file.
pub objects: BTreeMap<ObjectId, Object>,
/// Current maximum object id within the document.
pub max_id: u32,
/// Current maximum object id within Bookmarks.
pub max_bookmark_id: u32,
/// The bookmarks in the document. Render at the very end of document after renumbering objects.
pub bookmarks: Vec<u32>,
/// used to locate a stored Bookmark so children can be appended to it via its id. Otherwise we
/// need to do recrusive lookups and returns on the bookmarks internal layout Vec
pub bookmark_table: HashMap<u32, Bookmark>,
}
PDF Structure
Recall that a PDF has the following structure in the following order (see appendix on incremental updates for a variation in this structure):

- The header contains the version info
- The body contains all of the objects to be rendered
- The
xref(cross-reference) table contains location information for all of the objects in the PDF and whether or not each should be used - The trailer, which is the first thing PDF readers are meant to look at. It indicates where to find the
xreftable (via astartxrefentry), as well as the location of some special objects
How lopdf works through a PDF
This section describes how lopdf parses a document.
PDF parsing is based around this object:
pub struct Reader<'a> {
// PDF input data
buffer: &'a [u8],
// The document being created from the parsing process
document: Document,
}
And the primary parsing method which is dissected below:
fn read(mut self) -> Result<Document> {
// -- snip --
}
Below, the details of the read method are described.
1. Parsing the version into a String
The version is parsed into a String by a parser that:
- Expects
%PDF-at the beginning of the document - Taking until a newline or return is encountered
- Expects newline and optionally, comments
- Maps the output into a String with
str::from_utf8
2. Attempting to locate the start of the final xref table
Recall that the a PDF will indicate where to find the xref table with an entry in the trailer like so:
startxref
2714
%%EOF
In the above example, the startxref entry indicates that the xref table starts at the 2,714th byte in the document.
lopdf finds the last instance of startxef by:
- Setting a cursor near the end of the document (512 bytes from the end, or 0 bytes if the doc is 512 bytes long)
- Looking for the first occurrence of
%%EOFafter the cursor above - Looking for
startxref, followed by a number, all within the 25 characters preceding%%EOF
If there aren’t 25 characters preceding %%EOF, or startxref and a number isn’t found in those preceding characters, or if %%EOF isn’t found, lopdf returns an error and attempts no further parsing of the document.
🚨 Potential lopdf bug: If the PDF is incrementally updated and there are multiple xref tables, it seems plausible that going back 512 bytes from the end of the document might not result in taking the final startxref entry.
3. Parsing the final xref table and trailer
Here’s an example xref:
xref
0 11
0000000000 65535 f
0000000019 00000 n
0000000093 00000 n
0000000147 00000 n
0000000222 00000 n
0000000390 00000 n
0000001522 00000 n
0000001690 00000 n
0000002423 00000 n
0000002456 00000 n
0000002574 00000 n
As you can see, the xref table is not in the same type of format as the rest of the PDF – it isn’t composed of primitives. So it has to be stored in its own data structure, which lopdf parses into using a low-level byte parser like nom:
#[derive(Debug, Clone)]
pub struct Xref {
/// Entries for indirect object.
pub entries: BTreeMap<u32, XrefEntry>,
/// Total number of entries (including free entries), equal to the highest object number plus 1.
pub size: u32,
}
#[derive(Debug, Clone)]
pub enum XrefEntry {
Free,
Normal { offset: u32, generation: u16 },
Compressed { container: u32, index: u16 },
}
lopdf also implements a number of methods on Xref geared around manipulating the entries dictionary (adding new entries, removing entries, and so on).
The trailer, on the other hand, is a simple dictionary object:
trailer
<<
/Size 11
/Root 1 0 R
/Info 10 0 R
>>
…and is parsed into lopdf’s Dictionary representation.
4. Extending the final xref with any preceding xrefs
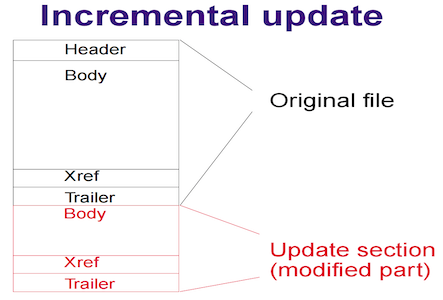
Recall that a PDF using the incremental update pattern will have multiple bodies, xrefs, and trailers.
lopdf attempts to parse the final xref and final trailer first.
If the PDF uses incremental updates, the last trailer in the document will have a reference to the second-to-last trailer, which will reference the third-to-last, and so on.
Previous-trailer references looks like:
trailer
<<
-- snip --
/Prev 406
>>
where 406 is a reference to the byte offset for the previous version’s xref table.
Using the Prev reference to the prior xref table, lopdf:
- Parses the
xreftable and trailer, - Appends the new
xrefto the finalxref. - Additionally, if a
XRefStmentry is present in the trailer, lopdf parses the cross-reference stream pointed by theXRefSteamand appends it to the finalxref. - Looks for a
Preventry on the previousxreftable, and if found, repeats this process starting at step 1
By iterating through prior xref tables in an incrementally-updated PDF, and adding those entries to the final xref, lopdf is able to build up a view of all of the objects in the PDF.
5. Comparing the calculated xref count vs. max xref ID
After it has iterated through all of the previous xrefs, lopdf then examins the maximum ID key of the final xref, and compares it to the number of entries in the final xref1. If the two don’t match, lopdf issues a warning and manually overwrites the size entry on the Xref struct to match the max ID.
6. Setting some document metadata
After processing the xref table(s) and the xref count, lopdf sets some document metadata on the Document instance:
self.document.version = version;
self.document.max_id = xref.size - 1;
self.document.trailer = trailer;
self.document.reference_table = xref;
7. Parsing the document objects
Now that lopdf has parsed all of the xref entries, it can actually attempt to parse each object in the xref and place each object into the Document instance’s objects BTree.
lopdf establishes a mutexed vector that can contain all of the parsed Objects:
let object_streams: Mutex<Vec<(ObjectId, Object)>> = Mutex::new(vec![]);
A mutex is needed because the parsing can be done using a parallel iterator, via rayon.
Either sequentially or in parallel, lopdf iterates over the entries in the final xref (which, recall, will contain any entries from the previous xrefs in the file), and applies a callback, entries_filter_map:
#[cfg(feature = "rayon")]
{
self.document.objects = self
.document
.reference_table
.entries
.par_iter()
.filter_map(entries_filter_map)
.collect();
}
#[cfg(not(feature = "rayon"))]
{
self.document.objects = self
.document
.reference_table
.entries
.iter()
.filter_map(entries_filter_map)
.collect();
}
The callback performs these steps on each XrefEntry:
- If the
XrefEntryisFreeorCompressed, the callback returns early with aNone - Otherwise, the
XrefEntryisNormal, and so the callback parses theObjectIdandObject - If the object has a stream and is of type
ObjStmthen it is an object that contains a stream of other objects, and the callback appends those objects to theobject_streamsmutex vector.- If the object has a stream, but is not of type
ObjStm, and if it is empty, then itsobject_idis appended to azero_length_streamsmutexed vector. See below for rationale
- If the object has a stream, but is not of type
- The
object_idand theobjectare returned from the callback (although unused since the callback appends to theobject_streamsmutex vector as a side effect)
lopdf then extends the Document’s objects entry:
self.document.objects.extend(object_streams.into_inner().unwrap());
8. Returning the document
Finally, lopdf returns the Document from the Reader:
fn read(mut self) -> Result<Document> {
// -- snip --
Ok(self.document)
}
Appendix
Incrementally Updated PDFs
Incremental updates are a pattern PDFs support that essentially appends new PDFs to the existing PDF file. This is a useful pattern because it means that restoring to an older version is as simple as deleting lines from the end of the file.
PDF Primitives and the Object enum
These are the primitives that compose PDF objects
- Null
- Boolean
- Integer
- Real
- Name
- String
- Array
- Dictionary (where the value is any of these primitives, including another Dictionary)
- Stream
- Reference
/// Basic PDF object types defined in an enum.
#[derive(Clone)]
pub enum Object {
Null,
Boolean(bool),
Integer(i64),
Real(f64),
Name(Vec<u8>),
String(Vec<u8>, StringFormat),
Array(Vec<Object>),
Dictionary(Dictionary),
Stream(Stream),
Reference(ObjectId),
}
Dictionary struct
The dictionary primitive is represented like so:
/// Dictionary object.
#[derive(Clone, Default)]
pub struct Dictionary(LinkedHashMap<Vec<u8>, Object>);
Where Object is the enum of all primitives.
The dictionary has a number of methods implemented:
has()- indicate whether the dictionary contains a given keyget()- get a given object for a given key (or error if no value found)get_deref()- get the given object, dereferencedget_mut()- get an object mutablyset()- insert an objectlen()- dictionary lengthis_empty()- indicate whether the dictionary’s emptyremove()- remove an object from the dictionary (if it’s there) and return ittype_name()- get the type of the object
… and so on.
XRefStm
A reference, that may be found in a trailer, pointing to a cross-reference stream.
Cross reference stream
A regular object that can be used to encode the xref data that would otherwise be found in an xref table.
Example:
12 0 obj
<<
/Type /XRef
/Size ...
/Root ...
>>
stream
...stream data containing cross-reference info...
endstream
endobj
Document
/// PDF document.
#[derive(Debug, Clone)]
pub struct Document {
/// The version of the PDF specification to which the file conforms.
pub version: String,
/// The trailer gives the location of the cross-reference table and of certain special objects.
pub trailer: Dictionary,
/// The cross-reference table contains locations of the indirect objects.
pub reference_table: Xref,
/// The objects that make up the document contained in the file.
pub objects: BTreeMap<ObjectId, Object>,
/// Current maximum object id within the document.
pub max_id: u32,
/// Current maximum object id within Bookmarks.
pub max_bookmark_id: u32,
/// The bookmarks in the document. Render at the very end of document after renumbering objects.
pub bookmarks: Vec<u32>,
/// used to locate a stored Bookmark so children can be appended to it via its id. Otherwise we
/// need to do recrusive lookups and returns on the bookmarks internal layout Vec
pub bookmark_table: HashMap<u32, Bookmark>,
}
Xref and XrefEntry
#[derive(Debug, Clone)]
pub struct Xref {
/// Entries for indirect object.
pub entries: BTreeMap<u32, XrefEntry>,
/// Total number of entries (including free entries), equal to the highest object number plus 1.
pub size: u32,
}
#[derive(Debug, Clone)]
pub enum XrefEntry {
Free,
Normal { offset: u32, generation: u16 },
Compressed { container: u32, index: u16 },
}
ObjectId
/// Object identifier consists of two parts: object number and generation number.
pub type ObjectId = (u32, u16);